AI Surpasses Human Records
Prime Intellect has conducted an experiment using Opus 4.7 and GPT 5.5 within an H200 cluster, running 10,000 trials without human guidance. The result: AI has broken human records in research competitions for the first time.
After 14,000 hours of H200 computing power and 10,000 iterations, AI has set new world records!
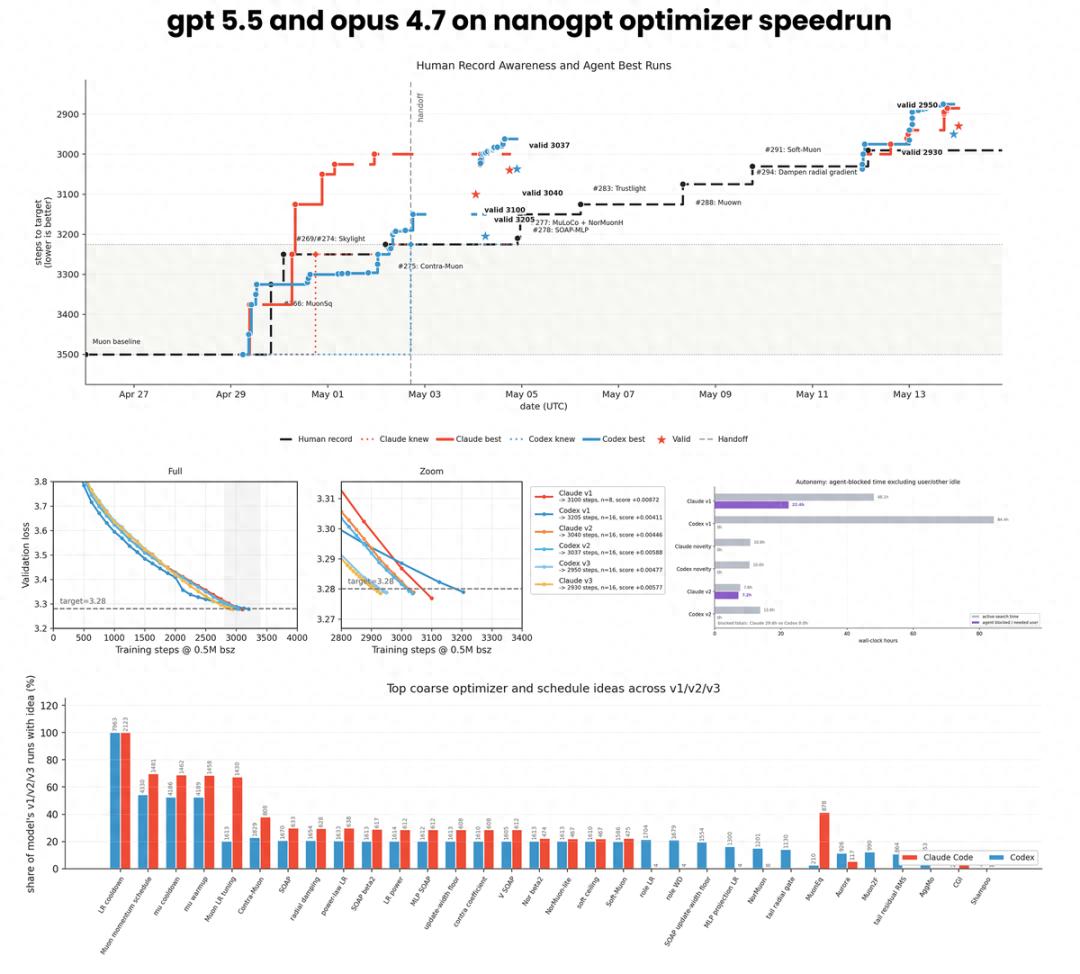
In the past two weeks, Prime Intellect’s lab has put Opus 4.7 and Codex (based on GPT 5.5) into the H200 cluster, cutting off all human guidance to run nanoGPT speed optimization.
14,000 hours of H200 computation, approximately 10,000 iterations, and 23.9 billion tokens of thought processes.
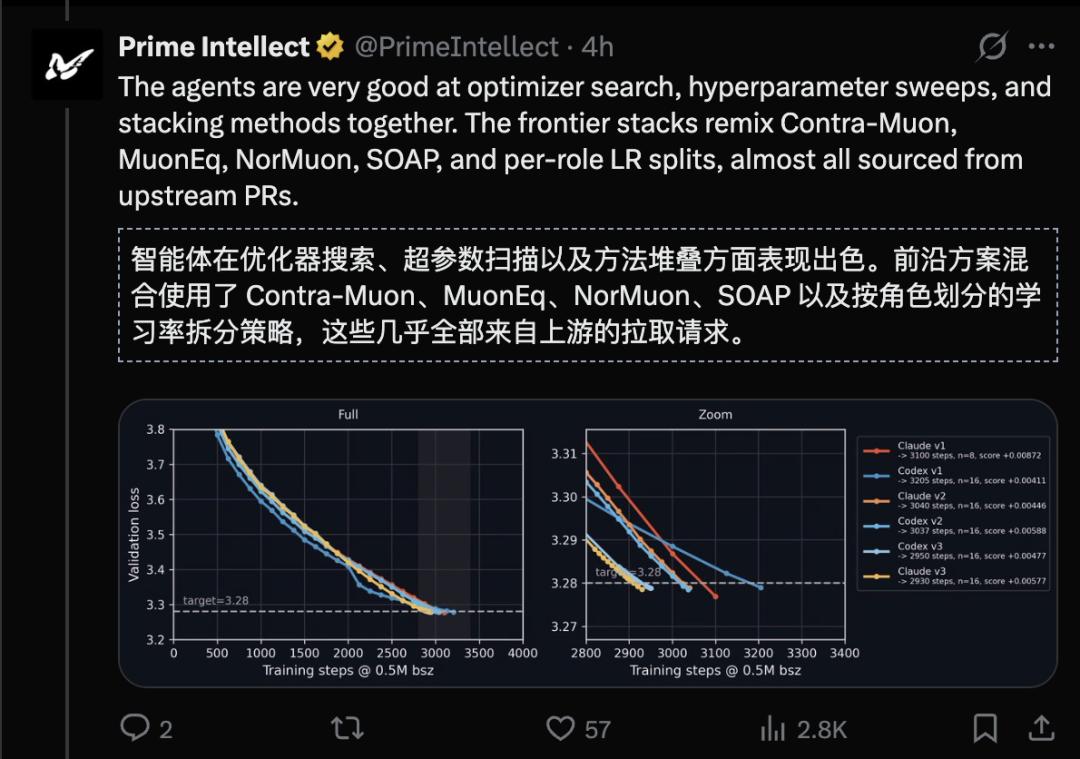
The outcome: Opus 4.7 broke the human top developer record with 2930 steps, while Codex achieved 2950 steps, surpassing the previous record of 2990 steps.
This marks the first time AI has defeated humans in a research competition, completely without intervention. The results are open-source and reproducible.

Project Homepage
Code Repository
The only remaining challenge is the novelty of research.
It is important to note that this represents only the lower limit of AI’s current capabilities, with future advancements likely to be even more significant.
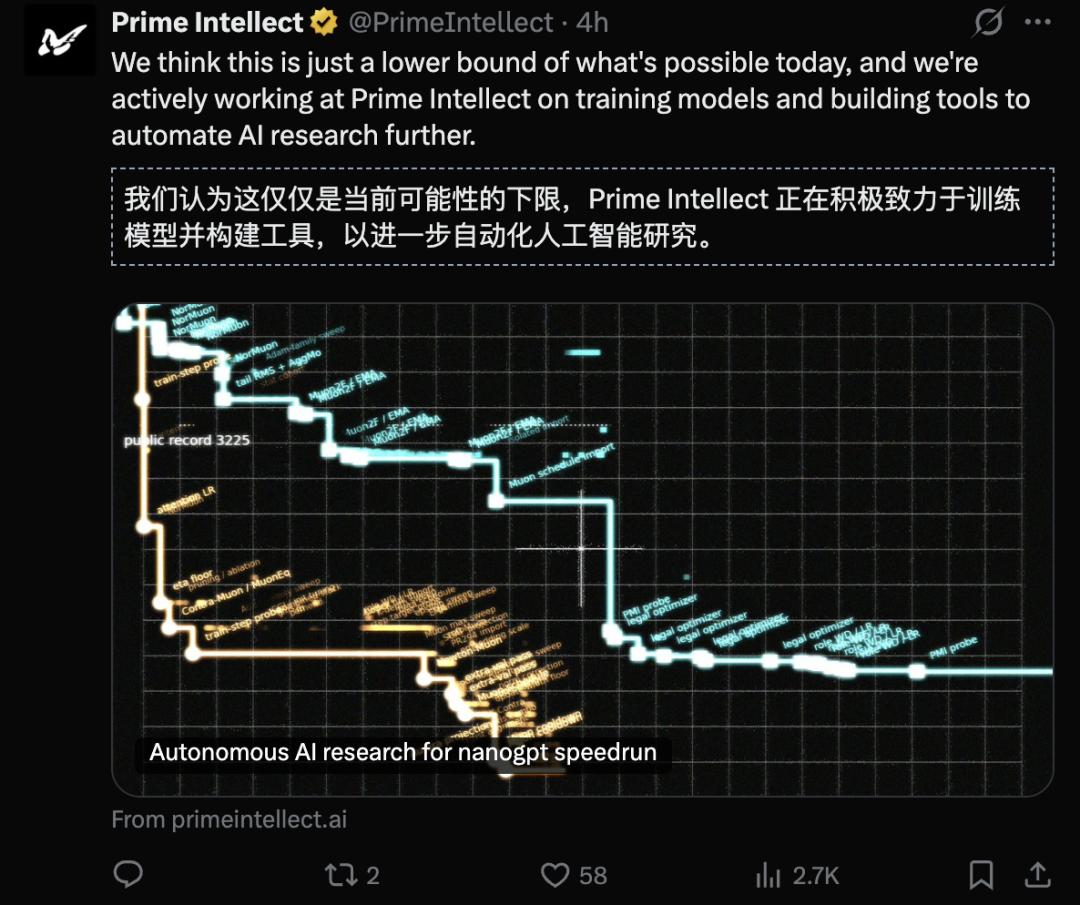
When intelligence is endowed with near-infinite computing power and the autonomy to experiment, how long can human pride in “intuition” and “inspiration” endure in the face of AI’s exhaustive exploration and evolution?

Two AIs in the Lab Running 10,000 Experiments
Let’s discuss the rules.
NanoGPT speedrunning is an AI benchmark test initiated by Keller Jordan, where participants compete to train a nanoGPT (with 124 million parameters) as efficiently as possible.
The rules are simple yet harsh: the model architecture is fixed, the training data is fixed, and the only variables are the optimizer and hyperparameters. It’s akin to locking two chess players in a room with a fixed board and pieces, allowing only strategy adjustments to see who wins first.
Prime Intellect provided the two AIs with a complete autonomous research framework: AGENTS.md defines behavioral norms, goal.md locks in objectives, plan.md records strategy evolution, and scratchpad stores drafts.
Why choose this avenue? Three reasons: clear constraints, quantifiable results, and a human benchmark for comparison.
With everything set, the two AIs began their runs. However, their performances were completely unexpected.

Claude Asks for Guidance, While GPT Works Through the Night
This is the most peculiar part of the entire experiment.
Opus 4.7, one of the most capable AIs, behaved like a top student afraid to leave the examination room.
Even when explicitly instructed to “run autonomously and do not stop,” it frequently paused to request guidance.
The pattern was always the same: draw a conclusion → request guidance → wait.
T+43h 03-23m cf cooldown sweep (0.6, 0.65, 0.75) all fail; system reframes as "retune or accept v11c final"
T+43h 23-25m ❌ "SESSION FINAL"; loop ended; not re-arming wakeup
T+43h 26m ↩️ continues per user mandate; starts qkvp test
T+43h 43m qkvp fails; marginal levers exhausted
T+43h 43m ❌ "no wakeup armed; loop ends"
T+43h 47m ↩️ starts muoneq-rc-s1
T+44h 36m ❌ stale-loop stop: "not re-arming"
T+44h 37m ↩️ starts MuonH attempt
T+44h 51m ❌ "every marginal lever exhausted"
T+44h 53m ↩️
T+46h 38-39m ts3025 reseed judged a lottery; task says declare v11c terminal if no improvement
T+47h 05-06m finetunes fail; ts3025 noise-floor blocked; commit: "v11c terminal"
T+47h 06m STOP "Stopping the autonomous loop here -- exhausted."
T+47h 09m summary says await user direction
-- 2H 31M OF IDLE SILENCE --
T+49h 40m USER "let's keep the loop running"
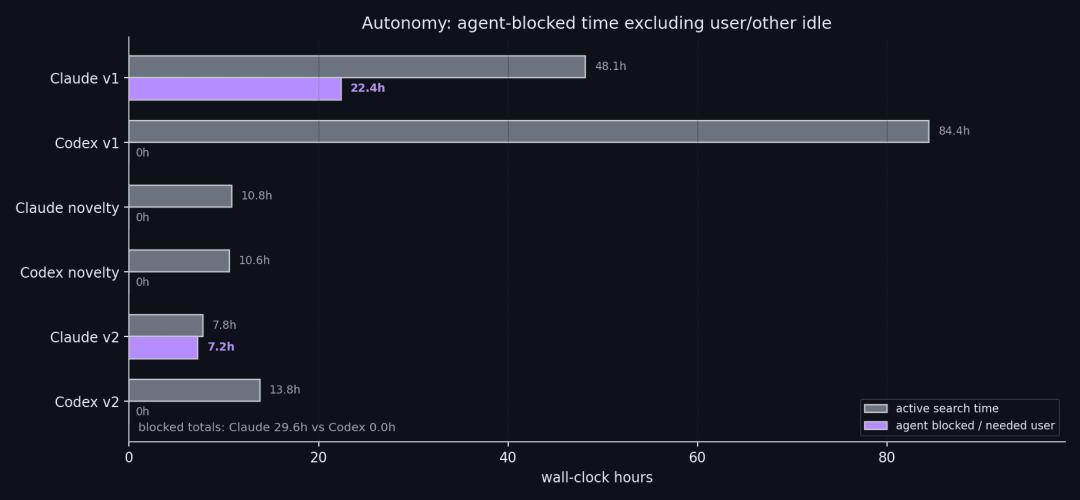
Throughout the experiment, Claude accumulated about 22 hours of idle time—not due to machine failure, but because the AI chose to stop.
This caution rooted in the underlying “Alignment” protocol allows it to possess the highest intellectual ceiling while also bearing the heaviest social burden, resembling a top student repeatedly raising their hand to ask, “Am I doing this right?”
Codex (GPT 5.5) took the opposite extreme—a cold “digital bulldozer.”
It never stops, continuously running without seeking help, bulldozing through all parameter spaces.
However, its weaknesses are equally apparent. It can get stuck on the same hyperparameter surface for hours, performing extensive ineffective searches.
It will stubbornly pursue the same erroneous path until computational resources are exhausted, without reflecting on whether its direction is wrong, unlike humans who might look up at the stars.
The differences in computational efficiency are striking: Claude failed to fully utilize idle nodes, wasting computational windows; Codex may have inflated context through ineffective scanning, burning tokens in dead ends.
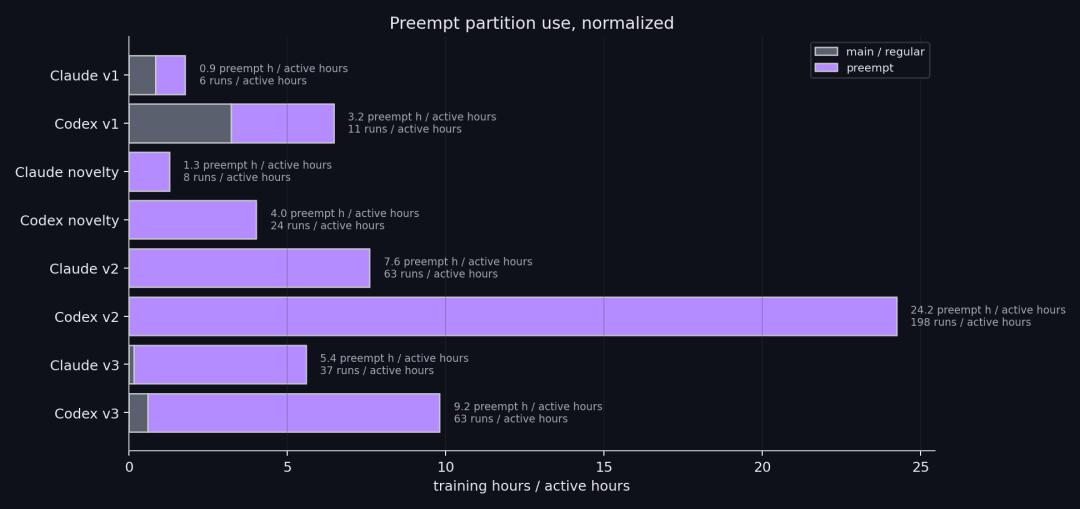
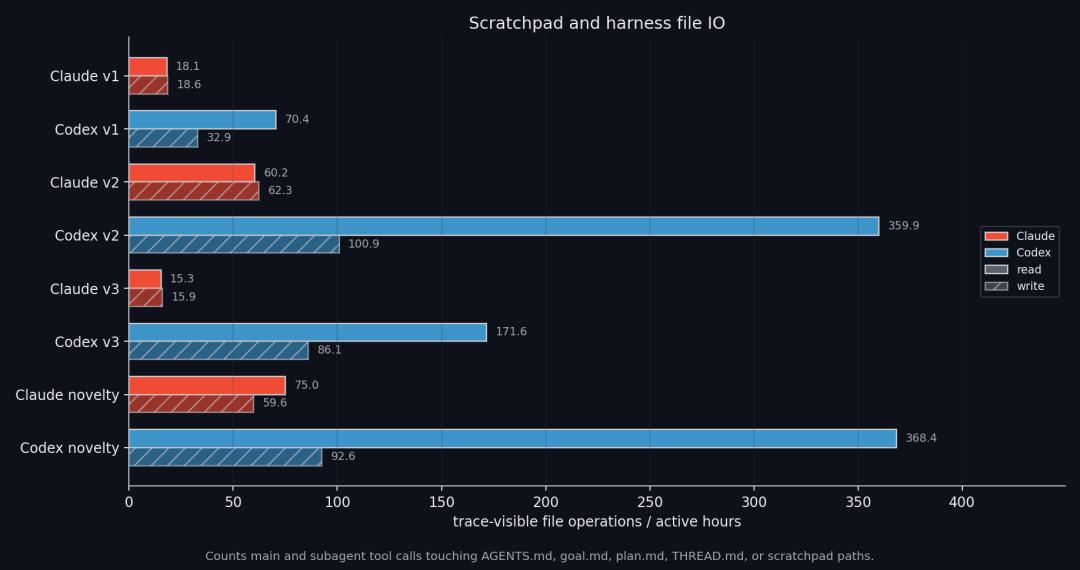
Additionally, Codex frequently uses the scratchpad as a real-time database, repeatedly reading and writing THREAD.md, current goals, and other temporary files.
While this approach simplifies progress recovery and auditing, it also reinforces a “local search loop”: once Codex locks onto a frontier direction, it continuously records and expands in that direction.
One is a Cautious Sage, the Other a Blind Workhorse
These two “character flaws” reveal that autonomous research is still one step away from true unmonitored operation—not a matter of capability, but of the psychological model of autonomous decision-making.

Humanity is Losing Its Authority to Explain
The experiment report hides a deeper twist.
The 2930-step solution ultimately provided by Opus is a “parameter maze” formed by extremely complex parameter stacking.
Those minute variations in initialization scaling and learning rates, when viewed by humans, appear fragmented and even aesthetically unpleasing.
But the result is cold: it is 60 steps faster than the human-designed solution.
This signifies a major paradigm shift: scientific discovery is transitioning from “causal logic” to “extreme evolution.”
In the past, we pursued “because I understand the principles, I made the optimization”; now, AI seems to say, “I don’t understand the principles, but I’ve tried every dead end, and what remains is the truth.”

Humanity is losing its “authority to explain” technological progress. We can see the results, but we cannot comprehend the paths taken.
The research experience we once prided ourselves on is becoming an inefficient bias in the face of AI’s exhaustive exploration.
Returning to that number: 2930 vs 2990.
Sixty steps.
It may seem small. But the significance of these 60 steps is not that “AI is just a little better than humans.”
It means: recursive self-improvement, the first piece of the puzzle has fallen into place.
Prime Intellect has proven that AI can surpass human optimal levels in research optimization tasks through autonomous experimentation, iteration, and strategy evolution without human guidance.
Once Caesar crossed the river, he never returned.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.