Artificial intelligence is being reshaped by large models. These systems have changed how people understand technology and are quietly transforming many industries, but they also bring risks and challenges. This article explains where large models came from, what they can do, how they are built, where they are used, and what problems remain.

Large models such as the generative pre-trained transformer (GPT) series have achieved major breakthroughs in natural language processing (NLP), repeatedly setting new performance benchmarks across language tasks. Beyond language, large models have also shown strong advantages in image processing, audio processing, physiological signals, and other data modalities. They are being rapidly applied in education, healthcare, finance, and other fields, especially in content generation.
Today, many frontier technologies around large models still need further development, while problems such as bias and privacy leakage also need urgent solutions. This article reviews the past and present of large models, discusses frontier issues, and looks at future directions.
![]()
Origins of Large Models
In November 2022, the well-known U.S. AI research company OpenAI released ChatGPT, an AI chatbot based on the large language model GPT-3.5. With fluent language expression, strong problem-solving ability, and a large knowledge base, it attracted global attention. Less than two months after launch, ChatGPT surpassed 100 million monthly active users, becoming the fastest-growing consumer application in history. Since then, many industries have felt the influence of large models, and research enthusiasm around large models has surged worldwide.
The origins of large models can be traced back to the early stage of AI research in the twentieth century, when research focused mainly on logical reasoning and expert systems. However, these approaches were limited by hard-coded knowledge and rules, making it difficult to handle the complexity and diversity of natural language. With the rise of machine learning and deep learning, and the rapid improvement of hardware capabilities, training on large-scale datasets with complex neural networks became possible, ushering in the era of large models.
In 2017, Google introduced the Transformer architecture, which greatly improved sequence modeling by introducing the self-attention mechanism. It was especially effective in improving efficiency and accuracy when handling long-range dependencies. Since then, the idea of the pre-trained language model (PLM) has gradually become mainstream. PLMs are pre-trained on large-scale text datasets to capture general language patterns, and then fine-tuned for specific downstream tasks.
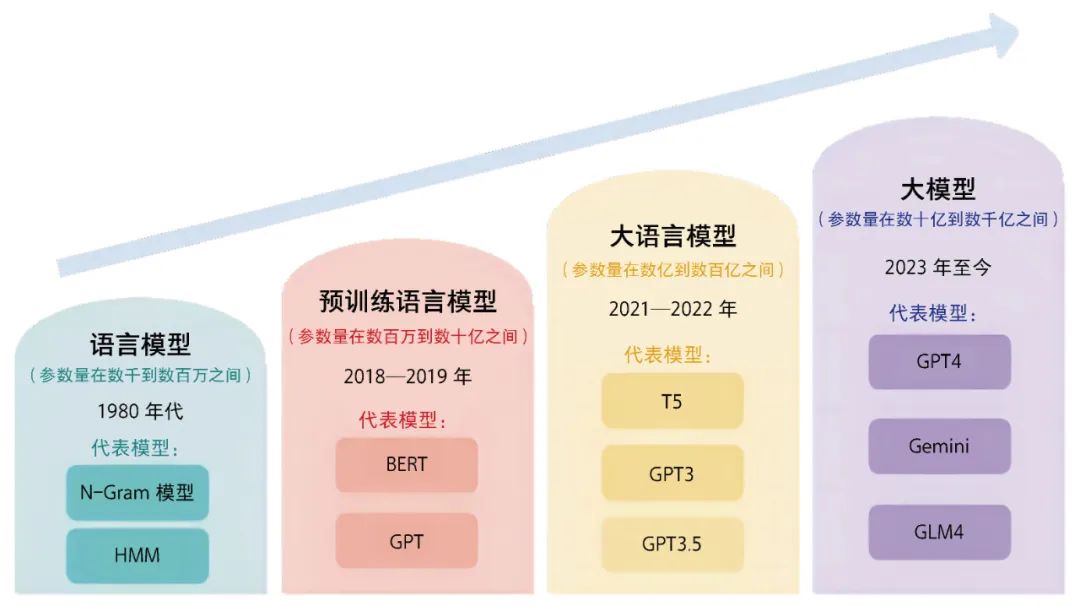
The evolution path of large models.
OpenAI’s GPT series is a representative example of generative pre-trained models. From GPT-1 to GPT-3.5, each generation significantly improved in scale, complexity, and performance. At the end of 2022, ChatGPT appeared as a chatbot. It could answer questions, write articles, program, and even imitate human conversation styles. Its broad answering ability gave people a new understanding of the general capabilities of large language models and greatly promoted the development of NLP.
However, the development of large models is not limited to text. As technology advances, multimodal large models have emerged. These models can understand and generate multiple data types at the same time, including text, images, and audio. In March 2023, OpenAI officially announced the multimodal large model GPT-4, adding image capabilities and improving language understanding accuracy. This marked an important transition from single-modality models to multimodal models. The essential differences among cross-modal data types create new and more complex requirements for model design and training, as well as unprecedented challenges.
![]()
Characteristics of Large Models
Large models usually refer to machine learning models with enormous numbers of parameters, especially in NLP, computer vision (CV), and multimodal applications. These models are based on pre-training. They understand and learn human language through NLP and complete tasks such as information retrieval, machine translation, text summarization, and code writing through human-machine dialogue.
Parameter Scale
Large models usually have more than 1 billion parameters, meaning that the model contains more than 1 billion learnable weights. These parameters are the foundation for learning and understanding data. During training, they are continuously adjusted to better map input data to output results. Increasing the number of parameters is directly related to stronger learning ability and higher complexity, enabling models to capture more subtle and deeper data features.
Types of Large Models
Large models can be classified by application field and function:
- Large language models: Focus on processing and understanding natural language text. They are commonly used for text generation, sentiment analysis, question-answering systems, and related tasks.
- Large vision models: Designed to process and understand visual information such as images and videos. They are used for image recognition, video analysis, image generation, and other visual tasks.
- Multimodal large models: Can process and understand two or more types of input data, such as text, images, and audio. By integrating information from different modalities, they can perform more complex and comprehensive tasks than single-modality models.
- Foundation large models: Usually refer to models that can be widely applied to many different tasks. During pre-training, they are not built for one specific application direction but instead learn broad general knowledge.
Capabilities of Large Models
The power of large models lies in their ability to understand and process highly complex data patterns:
- Generalization: Through pre-training on large amounts of data, large models learn universal language patterns and can show strong generalization when facing new tasks.
- Deep representation learning: Large parameter scales and deep network structures allow large models to build complex abstract representations and understand deep semantics and relationships behind data.
- Context understanding: In language models, large models can capture long-range dependencies and better understand context, which is crucial for subtle differences in language.
- Knowledge integration: Large models can integrate and use knowledge learned during pre-training. In some cases, they can show a degree of commonsense reasoning and problem-solving ability.
- Adaptability: Although large models learn general knowledge during pre-training, they can be fine-tuned for specific tasks, showing high flexibility and adaptability.
![]()
Technologies Behind Large Models
Modern large models integrate the ability to process many types of data. Their core technologies are designed to understand and generate information across different sensory modes, enabling tasks such as image captioning, visual question answering, and cross-modal translation. Several key technologies are central to large models.
Transformer Architecture
Most current large models are built on the Transformer architecture, or only the decoder part of the Transformer. This architecture captures global dependencies in input data through self-attention and can also capture complex relationships among elements from different modalities. For example, a multimodal Transformer can process image pixels and text words at the same time, using self-attention layers to learn associations between them. This enables large models to understand text, images, and other modalities, generate long text sequences, and maintain contextual coherence.
Supervised Fine-Tuning
Supervised fine-tuning (SFT) is a traditional fine-tuning method that uses labeled datasets to continue training a pre-trained large model. In large-model training, the SFT stage usually uses high-quality datasets. SFT adjusts the model parameters so that the model performs better on a specific task.
For example, to improve a model’s performance in legal consulting, one could use a dataset containing legal questions and professional lawyers’ answers for SFT. In SFT, the model usually tries to minimize the difference between predicted outputs and true labels, often through a loss function such as cross-entropy loss. This method is direct and simple and can quickly adapt a model to a new task. However, it also has limitations: it depends on high-quality labeled data and may cause the model to overfit the training data.
Reinforcement Learning from Human Feedback
Reinforcement learning from human feedback (RLHF) is a more complex training method that combines elements of supervised learning and reinforcement learning. First, the model is pre-trained on large amounts of unlabeled text, similar to the stage before SFT. Then human evaluators interact with the model or evaluate its outputs, providing feedback on performance. A reward model is trained with human feedback data to predict the scores that human evaluators might give. Finally, the reward model is used as a reward signal, and reinforcement learning is applied to optimize the original model’s parameters.
In this process, the model tries to maximize the expected reward it receives. The advantage of RLHF is that it can help the model learn more complex behaviors, especially when a task cannot be easily defined with simple correct-or-incorrect labels. RLHF can also help models better adapt to human preferences and values.
![]()
Applications of Large Models
Through enormous parameter counts, deep network structures, and broad pre-training, large models can capture complex data patterns and perform well in many fields. They can understand and generate natural language, process complex visual and multimodal information, and adapt to a variety of changing application scenarios.
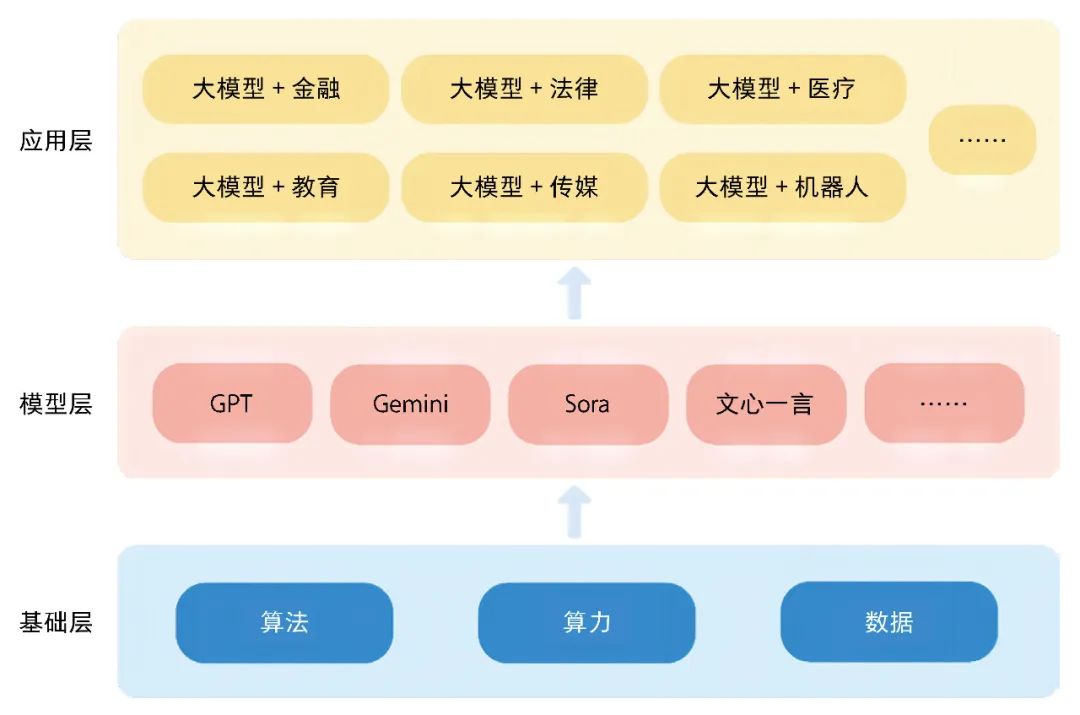
Ecosystem architecture of large models.
Natural Language Processing
Large models are widely used in NLP. For example, OpenAI’s GPT series can generate coherent and natural text and is used in chatbots, automated writing, and language translation. ChatGPT is a well-known product example.
In financial technology, large models are often used for risk assessment, trading algorithms, and credit scoring. They can analyze large amounts of financial data, predict market trends, and help financial institutions make better investment decisions.
In legal and compliance fields, large models can be used for document review, contract analysis, and case research. Through NLP, models can understand and analyze legal documents, improving the efficiency of legal professionals.
Recommendation systems are another application area. By serializing user behavior data into text, large models can predict users’ interests and recommend relevant products, films, music, and other content.
In games, large models can use their coding ability to generate complex game environments. They can also drive non-player characters (NPCs) to produce different conversations according to different player settings, creating a more realistic gaming experience.
Image Understanding and Generation
Current large models are not limited to text understanding. Their multimodal understanding also supports applications in images, such as automatic generation of paintings and videos. These models can imitate artists’ styles and create new artworks, assisting human creativity.
For example, OpenAI released Sora in February 2024. It can directly generate a video that meets user requirements from text input, offering a more convenient tool for film production.
In image processing, large models such as SegGPT are used for image recognition, classification, and generation. By learning from large amounts of paired image and text data, models can identify objects, faces, and scenes in images, and can be used in medical image analysis, autonomous vehicles, video surveillance, and other fields.
In medicine and biology, multimodal large models can be used for disease diagnosis, drug discovery, and gene editing. They can extract useful information from complex biomedical data, help doctors make more accurate diagnoses, and help researchers design new drugs.
Speech Recognition
Large models also play an important role in speech recognition. Through deep learning, models can convert speech into text, supporting voice assistants, real-time speech transcription, and automatic subtitle generation. Voice assistants on mobile phones are typical examples. By learning from large numbers of speech samples, these models can handle different accents, tones, and noise interference.
Large models can also be used in education, healthcare, agriculture, finance, and other industries. In education, for instance, large models can support personalized learning, automatic grading, and intelligent tutoring. They can provide customized teaching content according to a student’s learning situation and help students learn more efficiently.
Overall, large models show great potential across many fields because of their strong data processing and learning abilities. As technology continues to advance, large models are expected to play an even more important role in future development.
![]()
Development of Large Models
In today’s AI field, large models have become an unavoidable trend. As deep learning continues to advance, especially in NLP and CV, large models are pushing the frontiers of technology with their strong data processing and pattern recognition capabilities.
At the technical level, the development of large models has benefited from several key factors. The first is algorithmic innovation. Since the Transformer architecture was proposed, models such as BERT, the GPT series, and T5 have developed rapidly. Through pre-training and fine-tuning strategies, these models achieved leading performance on many NLP tasks.
The second factor is improved computing power. Advances in hardware such as graphics processing units (GPUs) and tensor processing units (TPUs) have made it possible to train models with billions or even tens of billions of parameters. Cloud computing platforms have also provided the necessary computing resources for training large models. At the same time, large-scale datasets have provided abundant training material. These datasets usually contain rich language expressions, scene information, and user interactions, allowing models to capture complex data distributions and language patterns.
At the application level, large models are developing mainly in two directions: large language models and multimodal large models. In large language models, GPT-3 was a milestone, with 175 billion parameters and remarkable language understanding and generation ability. The LLaMA series released by Meta AI then became popular in academia and industry because of its strong performance and relatively smaller model size. These models perform well not only on standard NLP tasks, but also show great potential in few-shot learning and transfer learning.
Multimodal large models extend this development by processing and understanding multiple input types, such as text, images, and audio. OpenAI’s DALL-E and CLIP are representative works in this direction. They can understand and generate images that match text descriptions, or understand text content through images. Google’s SimCLR was an important exploration in CV, using contrastive learning to extract image features effectively. Later, Google’s Gemini took an important step in native multimodality. It is pre-trained across different modalities and can process more complex inputs and outputs, such as images and audio. OpenAI’s Sora further expanded the application range of large models by automatically generating video content from input text, simulating interactions among people and environments in the physical and digital worlds to some extent.
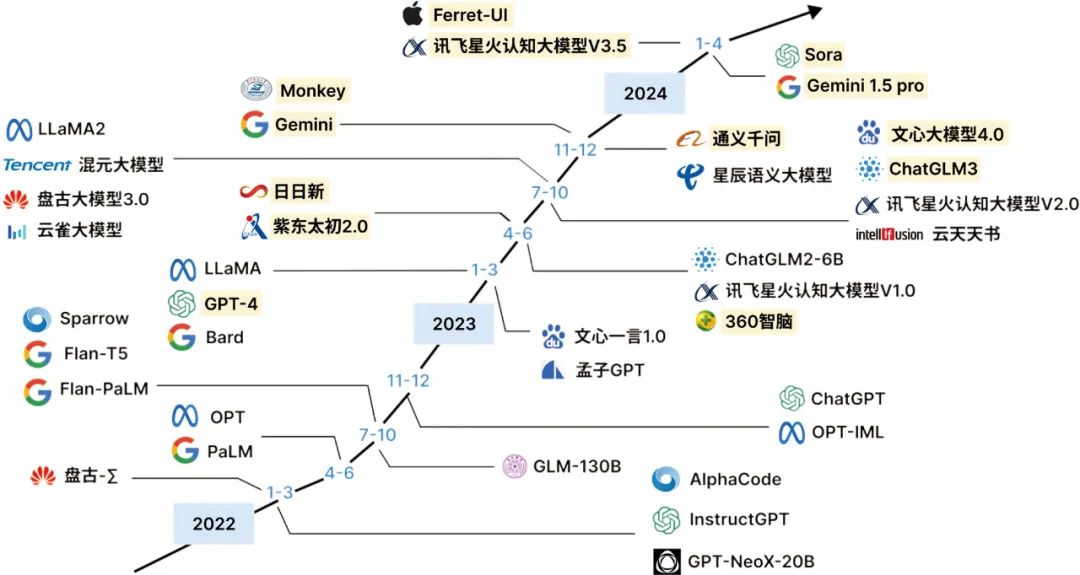
Overview of the development history of large models; highlighted items are multimodal models.
Chinese technology companies are also actively exploring large models. Baidu’s Ernie Bot, Alibaba’s Tongyi Qianwen, Huawei’s Pangu, and iFlytek Spark have appeared one after another. They perform well in general language understanding and generation and also show professional application capabilities in vertical fields such as healthcare, law, and tourism. For example, Ctrip Wendao focuses on question answering in tourism, NetEase Youdao’s Ziyue is applied in education, and JD Health’s Jingyi Qianxun provides medical consultation services.
![]()
Challenges Facing Large Models
Large models have become a focus in both academic research and industry because of their strong processing capabilities and broad application prospects. However, as these models continue to expand, the problems at the research frontier are becoming increasingly complex.
Model Size
Balancing model size and data scale is a major challenge. Although model performance often improves as the number of parameters increases, this growth brings enormous computing costs and higher requirements for data quality. Researchers are looking for ways to achieve the best balance between model size and data scale under limited computing resources. They are also exploring data augmentation, transfer learning, and model compression to reduce model size without sacrificing performance, with the goal of minimizing the operating cost of large models.
Network Architecture
Innovation in network architecture is also crucial. Almost all existing large models are based on the Transformer architecture. Although Transformers perform well in sequence data processing, their low computational efficiency and low parameter utilization can waste computing resources. These limitations have prompted researchers to design new architectures that improve efficiency and generalization by improving attention mechanisms, introducing sparsity, and using adaptive computation.
State-space-based models such as Mamba, proposed in December 2023, introduced selective mechanisms and addressed computational efficiency problems in existing Transformer architectures to a large extent. They are expected to become a possible foundation for the next generation of large models.
Prompt Engineering
When dealing with imbalanced datasets, prompt learning has emerged as a new paradigm. By embedding specific prompts into input data, prompt learning can help improve model performance on minority classes. However, designing effective prompts and determining whether those prompts are robust across different types of large models has become a specialized field: prompt engineering. How to combine prompts designed through prompt engineering with other large-model technologies still requires further research.
Contextual Reasoning
As model size grows, some untrained abilities such as contextual reasoning emerge. The appearance of these emergent capabilities suggests that large models may have internalized mechanisms closer to human cognition and learning. The nature, triggering conditions, and controllability of these emergent abilities are current research hotspots. They need to be explored more from the perspectives of cognitive science and neuroscience, with more reasonable explanations to help people understand how such abilities arise.
Knowledge Updating
Continuous knowledge updating is another important problem for large models. As knowledge keeps advancing, information inside a model may quickly become outdated. Researchers are exploring how to enable models to keep learning and integrate new knowledge while avoiding catastrophic forgetting, so that a model’s knowledge base remains up to date.
Explainability
Although large models perform well in many NLP and machine learning tasks, as parameter counts increase and network structures deepen, their decision-making processes become harder to explain. The black-box nature of large models makes it difficult for users to understand how they process input data and produce outputs. This creates a passive form of understanding: people know only the model’s output, but not why the model made that decision.
Privacy and Security
Training data for large models may include personally identifiable information, sensitive data, or business secrets. If such data is not properly protected, model training may create risks of privacy leakage or misuse. At the same time, large models themselves may contain sensitive information, such as memories acquired during training on sensitive data, which gives the model itself potential privacy risks.
Data Bias and Misleading Information
Large language models may output biased or misleading content. This can result from data collection methods, annotators’ subjective preferences, social and cultural factors, and other causes. When models are trained on biased data, they may mistakenly learn or amplify those biases, leading to unfair or discriminatory outcomes in real applications.
Solving these problems is essential for advancing large-model technology and expanding its applications. Each challenge that is addressed may help AI become more effective in real-world use and have a profound impact on human society.
![]()
The Future of Large Models
As AI technology develops and application scenarios for large models continue to expand, future trends in large-model technology are showing several new characteristics and directions.
Balancing Model Scale and Efficiency
Large-model technologies often require enormous computing resources and storage space. Future development will therefore focus on improving efficiency while maintaining model scale, so that practical application requirements can be met.
Sparse expert models are attracting attention as a new architectural approach. Compared with traditional dense models, sparse expert models reduce computing requirements by activating only model parameters related to the input data, thereby improving computational efficiency. In 2023, Google’s sparse expert model GLaM had seven times more parameters than GPT-3, but reduced energy consumption during training and computing resources needed for inference, while outperforming traditional models on multiple NLP tasks.
Deeper Knowledge Integration
Knowledge integration aims to enrich a model’s representation and decision-making capabilities by combining information from different data sources and knowledge domains. At present, many large models are trained and applied mainly for a single domain or single data modality, such as BERT in NLP and ViT in CV. In the real world, however, text, images, audio, and other types of information are often interconnected, and single-modality information is rarely enough for complex scenarios.
As CV, speech recognition, and related technologies continue to develop, future large models will place more emphasis on multimodal fusion: processing data from different modalities and enabling interaction among multiple forms of information. This capability will help large models better understand and process complex information.
In addition, large-model technology can be combined with external knowledge bases to further improve understanding and broaden application scope. This means that models can use not only internal language patterns and statistical information, but also external structured knowledge for reasoning and decision-making, helping them handle complex real-world problems. External knowledge can also strengthen the generalization ability of large models.
Exploration of Embodied Intelligence
Embodied intelligence refers to intelligent systems that perceive and act through a physical body. Such systems acquire information, understand problems, make decisions, and take action through interaction between an agent and its environment, thereby producing intelligent behavior.
The spread of large models has greatly accelerated the research, development, and implementation of embodied intelligence. Large language models are becoming key tools that help robots better understand and use high-level semantic knowledge. By automatically analyzing tasks and breaking them down into concrete actions, large-model technology makes interactions among robots, humans, and physical environments more natural, improving robotic intelligence.
For example, different tasks can be handled by different large models. A language model can be used for learning dialogue, a vision model for recognizing maps, and a multimodal model for controlling body movement. In this way, robots can learn concepts and direct actions more efficiently, while decomposing and executing all instructions through automated scheduling and collaboration enabled by large models. This integrated use of different models will bring new opportunities and challenges to intelligent robotics.
Explainability and Trustworthiness
As model scale increases, internal structures become more complex, making explainability and trustworthiness key concerns.
To improve explainability, researchers will work to develop new methods and technologies that allow large models to clearly explain their decision-making processes and the basis for generated results. This may involve more transparent model structures, such as transparent neural networks or interpretable attention mechanisms, as well as explanatory algorithms and tools that help users understand model outputs.
To improve trustworthiness, a series of measures will be adopted to reduce the likelihood that models produce erroneous or misleading information. One important direction is to introduce external information sources and give models the ability to access and cite those sources. This would allow models to use the most accurate and up-to-date information, improving output accuracy and reliability.
To increase transparency and trust, models will also provide citations related to external information sources, allowing users to review the sources and judge their reliability. Current large models with external information access and citation functions, such as Google’s REALM and Facebook’s RAG, are only the beginning of this field. Future models such as OpenAI’s WebGPT and DeepMind’s Sparrow will further promote this direction and build a stronger foundation for future applications of large-model technology.
Future development of large models will pay increasing attention to explainability and trustworthiness. This is not only an inevitable technical trend, but also a reasonable social demand for technological applications. Only by continuously improving explainability and trustworthiness can large-model technology be better applied across fields and contribute more to human society.
Conclusion
Large models have achieved breakthroughs and applications across many fields. They have refreshed performance benchmarks in language processing and shown great potential in image processing, audio processing, physiological signals, and other data modalities. At the same time, they face challenges such as privacy protection, bias, explainability, and trustworthiness.
Looking ahead, the development of large models remains full of possibilities. Society should actively use the opportunities they provide to promote intelligent transformation across industries, while also facing and solving the problems that accompany them. In this way, AI technology can develop in a healthy and sustainable direction and bring greater benefits to humanity.
References
- Chen Huimin, Liu Zhiyuan, Sun Maosong. Social Opportunities and Challenges in the Era of Large Language Models. Computer Research and Development, 2024-02-20 [accessed 2024-03-05]. http://kns.cnki.net/kcms/detail/11.1777.TP.20240219.1454.026.html.
- Wang Minghao, Yin Tao, Yang Hongjie, et al. Development and Application of Knowledge Graph and Large Model Technologies. Cyber Security and Data Governance, 2023, 42(S1): 126-131.
- Vaswani A, Shazeer N, Parmar N, et al. Attention is All You Need. Advances in Neural Information Processing Systems, 2017, 30.
- Zhao Chaoyang, Zhu Guibo, Wang Jinqiao. Insights from ChatGPT for Large Language Models and New Development Ideas for Multimodal Large Models. Data Analysis and Knowledge Discovery, 2023, 7(03): 26-35.
- Che Wanxiang, Dou Zhicheng, Feng Yansong, et al. Natural Language Processing in the Era of Large Models: Challenges, Opportunities, and Development. Scientia Sinica Informationis, 2023, 53(09): 1645-1687.
- Wu Hequan. Large Models Integrated into Cloud Platforms: From Informatization to Digital Intelligence. Journal of Chongqing University of Posts and Telecommunications (Natural Science Edition), 2024, 36(01): 1-8.
- Sun Bailin. Review of Large Models. Computer Simulation, 2024, 41(01): 1-7+24.
- Luo Jinzhao, Sun Yulong, Qian Zengzhi, et al. A Review and Prospect of Artificial Intelligence Large Models. Radio Engineering, 2023, 53(11): 2461-2472.
- Liu Xuebo, Hu Baotian, Chen Kehai, et al. Key Technologies and Future Development Directions of Large Models: Starting from ChatGPT. Bulletin of National Natural Science Foundation of China, 2023, 37(5): 758-766.
- Xu Yuemei, Hu Ling, Zhao Jiayi, et al. Technical Application Prospects and Risk Challenges of Large Language Models. Journal of Computer Applications, 2023, 43(S2): 1-8.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.